CMS Provider Dashboard (Grafana)
Amazon Managed Grafana snapshot.
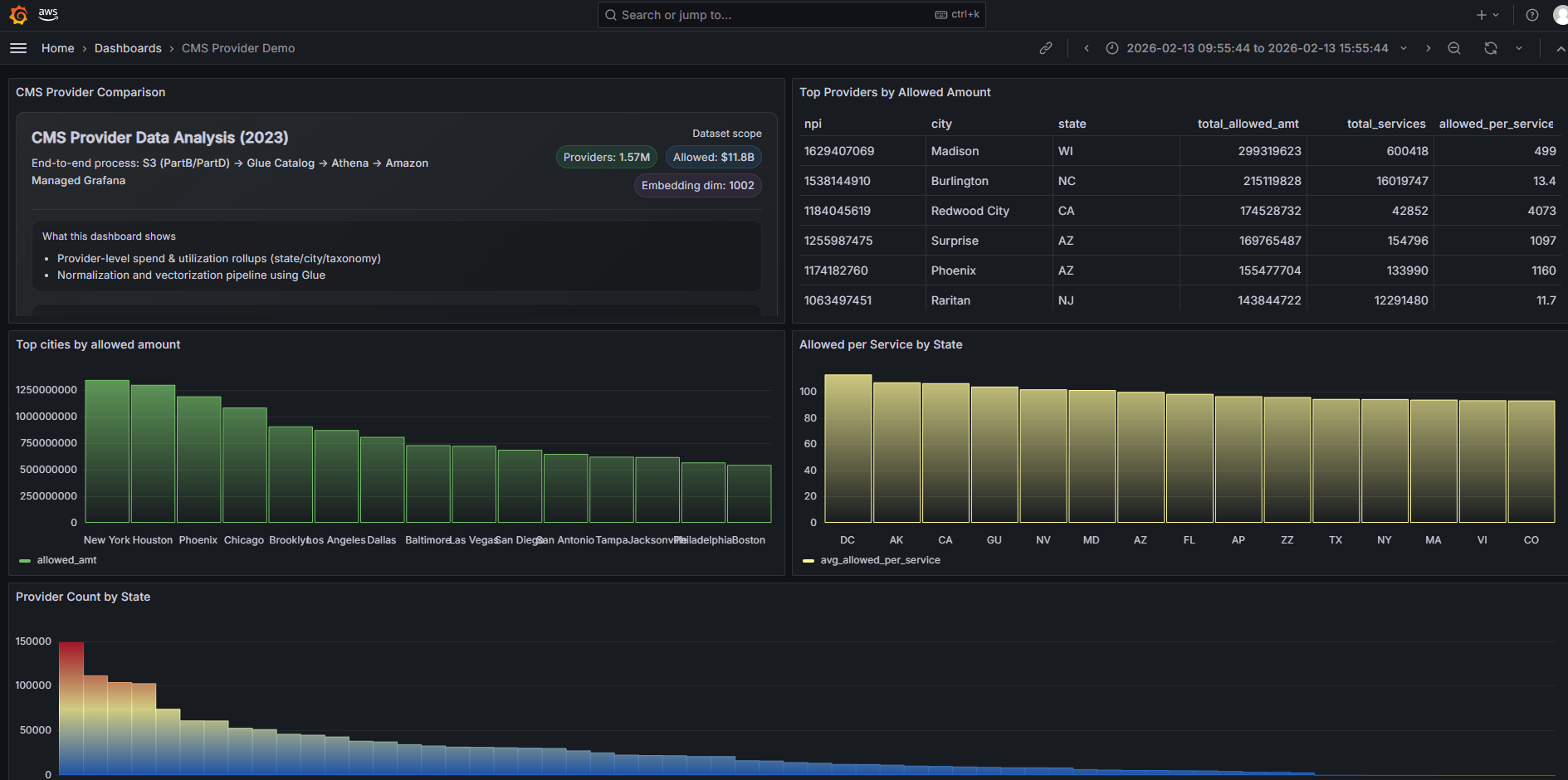
A system for comparing healthcare provider similarity using public CMS claims data across 1.57M providers (hostpitals, clinics, physician offices, etc). The app compares Medicare Part B (medical services/procedures) and Part D (prescription drugs) utilization patterns.
Claims data is processed on AWS into vector representations, modeled as a graph in Neo4j, and explained through retrieval-augmented LLM reasoning.
Amazon Managed Grafana snapshot.

Numbers correspond to components in the diagram.
Pipeline for transforming CMS datasets into provider vectors and a Neo4j similarity graph.

Numbers correspond to the diagram.
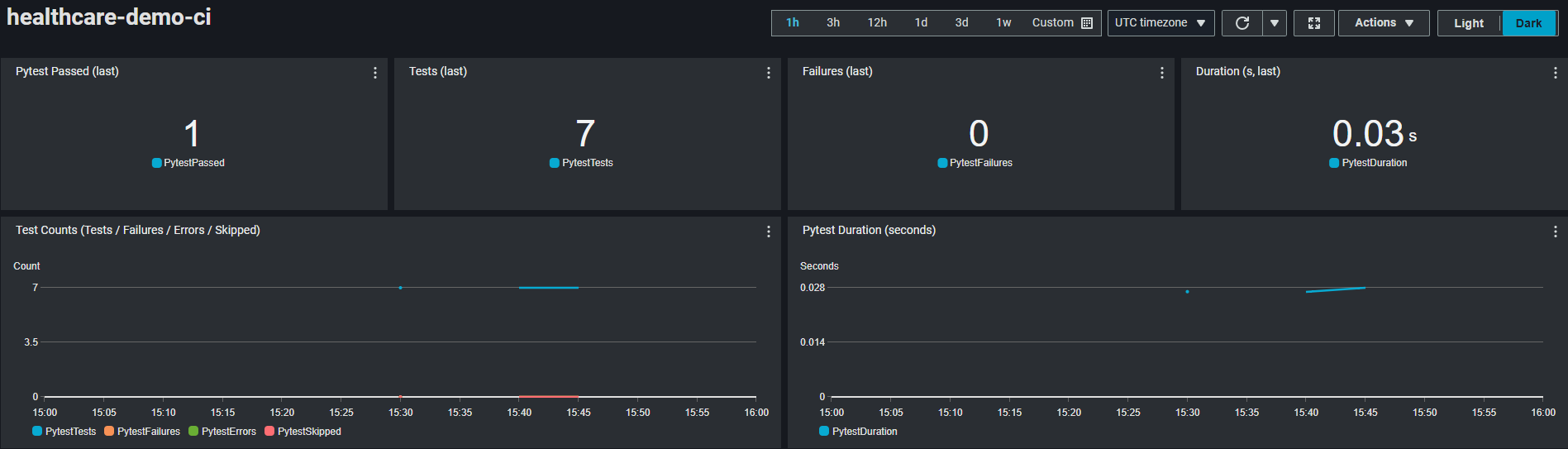
Live CloudWatch dashboard showing CodeBuild unit tests.